
了解了一下Http协议中的keep-alive机制以及Http版本更迭,记录一下
HTTP的Keep-Alive
在Http的headers中,有connection字段,可以设置为close或者keep-alive,自Http 1.1开始,这个字段的默认值改为了keep-alive,而在http 1.0中,这个字段的默认值则是close。
如果将该值设置为close,那么在这次请求完成后,将会断开网络连接,而如果设置为keep-alive,将不会断开连接,这样后面的请求仍然可以使用当前的网络连接。
这里的网络连接就是指TCP连接,因为http 1.1底层推荐使用的就是tcp连接,如果每个请求都需要重新建立tcp连接,经历三次握手四次挥手环节,并且由于tcp慢启动(慢启动是指每次TCP接收窗口收到确认时都会增长,增加的大小就是已确认段的数目。这种情况一直保持到要么没有收到一些段,要么窗口大小到达预先定义的阈值)的特性,将严重影响传输效率。
TCP的keepalive
其实tcp也存在保活机制,但是区别于http的keep-alive,http的keep-alive只会影响tcp连接的建立与断开的选择,而不会影响到tcp连接的原有保活机制。
tcp连接建立之后,可能会面临很多情况,比如某一方关机,断电等,没有来得及释放连接,但是另一方却不知情,如果没有保活机制,将一直维持着这个连接,造成资源的浪费。
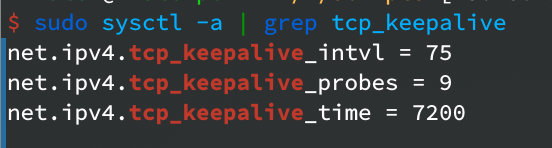
有了保活机制之后,一方可以向另一方发送心跳包,这里有三个参数(单位/s):
1 | tcp_keepalive_time // 心跳周期 |
即,在等待tcp_keepalive_time时间里没有数据交互,服务器会发送侦测包,如果收到答复,则重置时间,如果未收到答复,则等待tcp_keepalive_intcl的时间后再次发送,一共发送tcp_keepalive_probes次侦测包,如果都没有收到回复,则关闭该连接。
在linux中,可以查看当前系统的相关参数:
验证
keep-alive
首先用go搭一个简单的服务器
1 | package main |
用python脚本去发起请求:
1 | import requests |
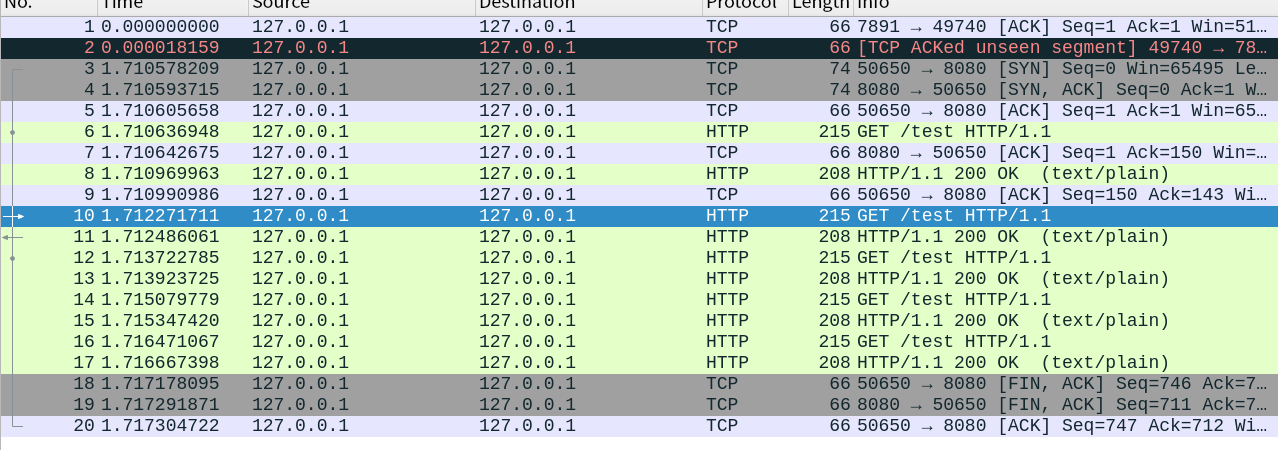
可以看到这里没有设置请求头的connection字段。从结果中可以看到连接并未断开:

从wireshark抓包结果中也可以看到除了第一次进行了握手操作,后续都没有再进行握手了:
close
接下来验证关闭连接
在python脚本中添加上请求头connection为close。

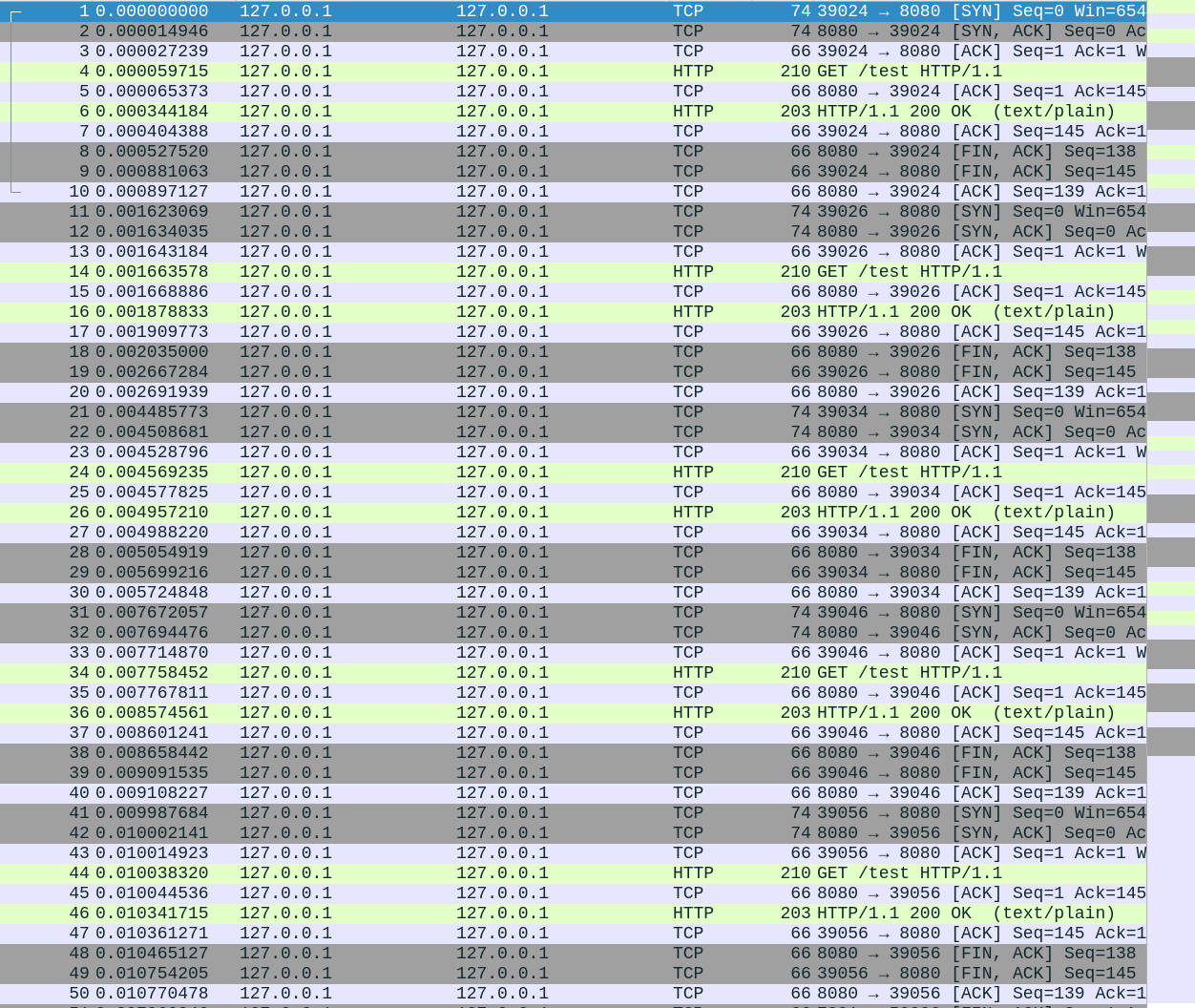
可以看到五次请求,经过了五次tcp的连接和断开连接过程。
go中http服务器的关闭连接逻辑
由于是用go的net/http包搭建的服务器,所以追踪一下源码看一下对于该字段的处理流程。
当服务端启动后,会调用socket的Accept()方法等待连接,当有连接建立后,就会新开一个协程,处理这个连接,serve方法就是协程会调用的方法(这里隐去了一些细节)。
1 | func (c *conn) serve(ctx context.Context) { |
第七行,可以看到这里有一个死循环,不断调用servers包下的readRequest()方法来读请求。进入该方法:
1 | func (c *conn) readRequest(ctx context.Context) (w *response, err error) { |
第三行可以看到再次调用了request包下的readRequest()方法:
1 | req.Close = shouldClose(req.ProtoMajor, req.ProtoMinor, req.Header, false) |
方法内部第七行语句设置了req的Close属性,传入的参数分别是http的大版本和小版本,req的Header以及一个bool类型的removeCloseHeader,这里恒为false。
1 | func shouldClose(major, minor int, header Header, removeCloseHeader bool) bool { |
可以看到在该方法中,取到请求头中的Connection字段,并且针对http1.0和1.1的不同进行赋值(1.0版本只有设置了keep-alive才是长连接,1.1版本只要没有设置close,就默认为keep-alive)。
然后再根据req对w进行赋值
1 | w = &response{ |
回到serve()方法,可以看到在本次请求执行结束后有如下语句,:
1 | if !w.shouldReuseConnection() { |
这里会进入到该条件分支,可以看到这里会进行return退出协程,而在上面定义了defer函数,在退出之前会进行执行,也就是断开tcp连接。
1 | defer func() { |
如果不进入return的分支,则会设置连接状态为StateIdle,表示可用,然后清空当前req,再次执行循环,通过w, err := c.readRequest(ctx)语句读请求。
这里要注意这里不是阻塞的,当网络数据还没有达到时,如果socket被设置为了阻塞模式,进行读取数据将导致当前协程被阻塞。go中当建立tcp连接时,已经将socket设置为了非阻塞模式。
1 | func sysSocket(family, sotype, proto int) (int, error) { |
其他
另外,在java中,一个连接最多处理100个请求

从图中可以看到在第101次请求到来时连接重新建立了,当然这个值也是可以设置的。
1 | /** |
在go中则没有这个限制。
Http 2.0
Http 1.1 的问题
Http 1.1版本存在一些问题,虽然通过keep-alive机制大幅提升了传输性能,但是一个很大的问题就是请求是顺序发送的,这样就可能存在head of line blocking问题,第一个请求如果被阻塞,后续的请求都将无法发送。另外,keep-alive对移动端app也用处不大,因为移动端的app的请求比较分散,时间跨度较大。这里也提出了一些方案,比如pipelining,请求不用等上一个请求返回之后再发送,但也存在一些问题,比如一些请求间可能有依赖关系,另外head of line blocking并没有完全解决。而且统一比较困难,所以大多数浏览器要么没有实现这个功能,要么默认禁止了这个功能。并且Http 1.1的头部是重复且巨大的,特别是带上了cookie的头部,每次请求都要重复发送,并且也没有服务器推送消息的功能。
SPDY
在Http 2.0之前,还存在一个SPDY协议,这是由google提出的,在2016年被废止。SPDY是在Http之下,在SSL之上,所以不会影响到Http协议,只是将Http包封装成一种新的frame格式。
SPDY相较于Http 1.1的进步有:
- 多路复用:通过多个请求stream共享一个tcp连接。(浏览器客户端在同一时间内,针对同一域名下的请求有一定数量限制,超过限制的请求会被阻塞,chrome是6个,这也就是为什么一些大型网站的cdn域名会有多个)
- 请求优先级:SPDY允许为每个request设置优先级
- header压缩:对Http的header进行压缩,因为header中大部分内容都是重复的并且非常重量级
- server推送:开启server push之后,server通过
X-Associated-Content header(X-开头的header都属于非标准的,自定义header)告知客户端会有新的内容推送过来。在用户第一次打开网站首页的时候,server将资源主动推送过来可以极大的提升用户体验。
Http 2.0 主要改动
客户端和服务端交流前需要协商使用什么版本的Http,如果单独加一个协商过程,则需要多一个RTT的延迟,SPDY的做法是在SSL层完成这个协商过程,google做了一个tls的扩展NPN(Next Protocol Negotiation),但最终http2.0没有使用NPN,而是ALPN(Application Layer Protocol Negotiation)。
相较于Http 1.1, 2.0版本有如下改动:
新的二进制格式
和SPDY的思路一样,Http 2.0也会将Http包封装成帧,相较于字符串形式的Http 1.1,二进制类型的帧则非常高效
连接共享
在Http 2.0的帧中,有stream id,所以这些帧可以并行发送,在server端再进行组合,并且也可以设置优先级。客户端的stream id是奇数,服务器则是偶数
header压缩
Http 1.1可以使用头字段Content-Encoding指定body的压缩方式,比如用gzip压缩,这样可以节约带宽,但报文中的另外一部分header,没有针对它的优化手段。
Http 2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。压缩算法是HPACK算法。
编码表是动态生成的,比如,第一次发送时头部中的user-agent字段数据有上百个字节,经过Huffman编码发送出去后,客户端和服务器双方都会更新自己的动态表,添加一个新的Index号62。那么在下一次发送的时候,就不用重复发这个字段的数据了,只用发1个字节的Index号就好了,因为双方都可以根据自己的动态表获取到字段的数据。
所以,使得动态表生效有一个前提:必须同一个连接上,重复传输完全相同的 HTTP 头部。如果消息字段在1个连接上只发送了1次,或者重复传输时,字段总是略有变化,动态表就无法被充分利用了。但是,动态表越大,占用的内存也就越大,如果占用了太多内存,是会影响服务器性能的,因此 Web 服务器都会提供类似 http2_max_requests 的配置,用于限制一个连接上能够传输的请求数量,避免动态表无限增大,请求数量到达上限后,就会关闭 Http 2.0连接来释放内存。
更安全的SSL
Http 2.0使用了tls的拓展ALPN来做协议升级,除此之外加密这块还有一个改动,Http 2.0对tls的安全性做了近一步加强,通过黑名单机制禁用了几百种不再安全的加密算法,一些加密算法可能还在被继续使用。如果在ssl协商过程当中,客户端和server的cipher suite没有交集,直接就会导致协商失败,从而请求失败。在server端部署Http 2.0的时候要特别注意这一点。
Http 3.0
Http 2.0 的问题
Http 2.0 是基于TCP协议来传输数据的,TCP是字节流协议,必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给Http应用,那么当前1个字节数据没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这1个字节数据到达时,Http 2.0应用层才能从内核中拿到数据,这就是 Http 2.0队头阻塞问题。
Http 3.0 简介
由于Http 2.0的队头阻塞问题是tcp协议带来的,所以Http 3.0抛弃了tcp协议,而是使用了udp协议。
Http3.0的前身是QUIC(Quick Udp Internet Connections)协议,也是google提出的。Quic协议处于Http和SSL层之间,所以Http3.0也叫Http Over Quic。传统的基于TCP的Http在正式传输之前需要进行TCP握手环节以及TLS协商环节,需要至少3-4个RTT时间才能正式传输数据,QUIC可以实现O RTT建链。
首次连接时,进行一次TLS协商,非首次连接如果之前的TLS协商还有效,就可以复用之前的协商结果
优势
前向安全
通俗来说,前向安全指的是密钥泄漏也不会让之前加密的数据被泄漏,影响的只有当前,对之前的数据无影响。QUIC协议首次连接时先后生成了两个加密密钥,由于config被客户端存储了,如果期间服务端私钥泄漏,那么可以根据K = mod p计算出密钥K。
如果一直使用这个密钥进行加解密,那么就可以用K解密所有历史消息,因此后续又生成了新密钥,使用其进行加解密,当时完成交互时则销毁,从而实现了前向安全。
前向纠错
QUIC每发送一组数据就对这组数据进行异或运算,并将结果作为一个FEC包发送出去,接收方收到这一组数据后根据数据包和FEC包即可进行校验和纠错。
连接迁移
TCP协议使用五元组来表示一条唯一的连接,当我们从4G环境切换到wifi环境时,手机的IP地址就会发生变化,这时必须创建新的TCP连接才能继续传输数据。
QUIC协议基于UDP实现摒弃了五元组的概念,使用64位的随机数作为连接的ID,并使用该ID表示连接。
基于QUIC协议之下,我们在日常wifi和4G切换时,或者不同基站之间切换都不会重连,从而提高业务层的体验。
- 本文标题:http的keep-alive探究
- 本文作者:Kale
- 创建时间:2022-08-31 10:59:39
- 本文链接:https://kalew515.com/2022/08/31/http的keep-alive探究/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!